What is a Neural Network?
Before we get started with the how of building a Neural Network, we need to understand the what first.
Neural networks can be intimidating, especially for people new to machine learning. However, this tutorial will break down how exactly a neural network works and you will have a working flexible neural network by the end. Let’s get started!
Understanding the process
With approximately 100 billion neurons, the human brain processes data at speeds as fast as 268 mph! In essence, a neural network is a collection of neurons connected by synapses. This collection is organized into three main layers: the input layer, the hidden layer, and the output layer. You can have many hidden layers, which is where the term deep learning comes into play. In an artifical neural network, there are several inputs, which are called features, and produce a single output, which is called a label.

The circles represent neurons while the lines represent synapses. The role of a synapse is to multiply the inputs and weights. You can think of weights as the “strength” of the connection between neurons. Weights primarily define the output of a neural network. However, they are highly flexible. After, an activation function is applied to return an output.
Here’s a brief overview of how a simple feedforward neural network works:
-
Takes inputs as a matrix (2D array of numbers)
-
Multiplies the input by a set weights (performs a dot product aka matrix multiplication)
-
Applies an activation function
-
Returns an output
-
Error is calculated by taking the difference from the desired output from the data and the predicted output. This creates our gradient descent, which we can use to alter the weights
-
The weights are then altered slightly according to the error.
-
To train, this process is repeated 1,000+ times. The more the data is trained upon, the more accurate our outputs will be.
At its core, neural networks are simple. They just perform a dot product with the input and weights and apply an activation function. When weights are adjusted via the gradient of loss function, the network adapts to the changes to produce more accurate outputs.
Our neural network will model a single hidden layer with three inputs and one output. In the network, we will be predicting the score of our exam based on the inputs of how many hours we studied and how many hours we slept the day before. Our test score is the output. Here’s our sample data of what we’ll be training our Neural Network on:
| Hours Studied, Hours Slept (input) | Test Score (output) |
|---|---|
| 2, 9 | 92 |
| 1, 5 | 86 |
| 3, 6 | 89 |
| 4, 8 | ? |
As you may have noticed, the ? in this case represents what we want our neural network to predict. In this case, we are predicting the test score of someone who studied for four hours and slept for eight hours based on their prior performance.
Forward Propagation
Let’s start coding this bad boy! Open up a new python file. You’ll want to import numpy as it will help us with certain calculations.
First, let’s import our data as numpy arrays using np.array. We’ll also want to normalize our units as our inputs are in hours, but our output is a test score from 0-100. Therefore, we need to scale our data by dividing by the maximum value for each variable.
import numpy as np
# X = (hours sleeping, hours studying), y = score on test
X = np.array(([2, 9], [1, 5], [3, 6]), dtype=float)
y = np.array(([92], [86], [89]), dtype=float)
# scale units
X = X/np.amax(X, axis=0) # maximum of X array
y = y/100 # max test score is 100
Next, let’s define a python class and write an init function where we’ll specify our parameters such as the input, hidden, and output layers.
class Neural_Network(object):
def __init__(self):
#parameters
self.inputSize = 2
self.outputSize = 1
self.hiddenSize = 3
It is time for our first calculation. Remember that our synapses perform a dot product, or matrix multiplication of the input and weight. Note that weights are generated randomly and between 0 and 1.
The calculations behind our network
In the data set, our input data, X, is a 3x2 matrix. Our output data, y, is a 3x1 matrix. Each element in matrix X needs to be multiplied by a corresponding weight and then added together with all the other results for each neuron in the hidden layer. Here’s how the first input data element (2 hours studying and 9 hours sleeping) would calculate an output in the network:
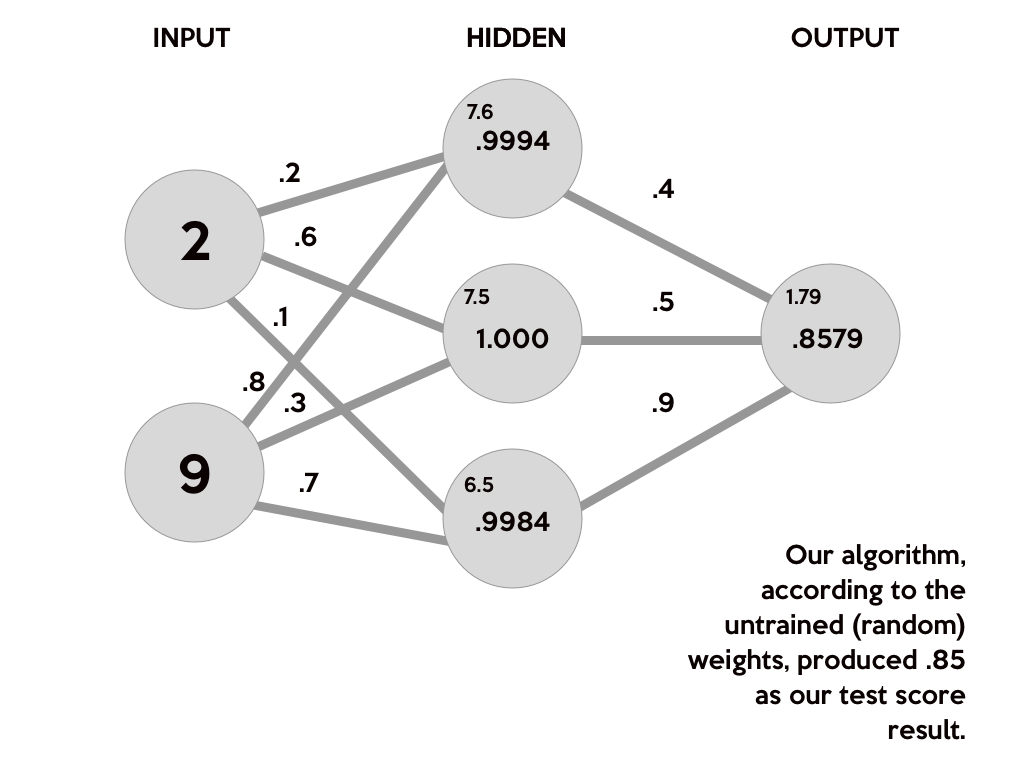
This image breaks down what our neural network actually does to produce an output. First, the products of the random generated weights (.2, .6, .1, .8, .3, .7) on each synapse and the corresponding inputs are summed to arrive as the first values of the hidden layer. These sums are in a smaller font as they are not the final values for the hidden layer.
(2 * .2) + (9 * .8) = 7.6
(2 * .6) + (9 * .3) = 3.9
(2 * .1) + (9 * .7) = 6.5
To get the final value for the hidden layer, we need to apply the activation function. The role of an activation function is to introduce nonlinearity. An advantage of this is that the output is mapped from a range of 0 and 1, making it easier to alter weights in the future.
There are many activation functions out there. In this case, we’ll stick to one of the more popular ones - the sigmoid function.
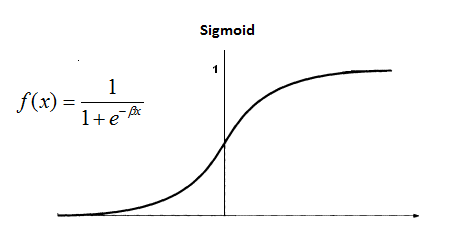
S(7.6) = 0.999499799
S(7.5) = 1.000553084
S(6.5) = 0.998498818
Now, we need to use matrix multiplication again, with another set of random weights, to calculate our output layer value.
(.9994 * .4) + (1.000 * .5) + (.9984 * .9) = 1.79832
Lastly, to normalize the output, we just apply the activation function again.
S(1.79832) = .8579443067
And, there you go! Theoretically, with those weights, out neural network will calculate .85 as our test score! However, our target was .92. Our result wasn’t poor, it just isn’t the best it can be. We just got a little lucky when I chose the random weights for this example.
How do we train our model to learn? Well, we’ll find out very soon. For now, let’s countinue coding our network.
If you are still confused, I highly reccomend you check out this informative video which explains the structure of a neural network with the same example.
Implementing the calculations
Now, let’s generate our weights randomly using np.random.randn(). Remember, we’ll need two sets of weights. One to go from the input to the hidden layer, and the other to go from the hidden to output layer.
#weights
self.W1 = np.random.randn(self.inputSize, self.hiddenSize) # (3x2) weight matrix from input to hidden layer
self.W2 = np.random.randn(self.hiddenSize, self.outputSize) # (3x1) weight matrix from hidden to output layer
Once we have all the variables set up, we are ready to write our forward propagation function. Let’s pass in our input, X, and in this example, we can use the variable z to simulate the activity between the input and output layers. As explained, we need to take a dot product of the inputs and weights, apply an activation function, take another dot product of the hidden layer and second set of weights, and lastly apply a final activation function to recieve our output:
def forward(self, X):
#forward propagation through our network
self.z = np.dot(X, self.W1) # dot product of X (input) and first set of 3x2 weights
self.z2 = self.sigmoid(self.z) # activation function
self.z3 = np.dot(self.z2, self.W2) # dot product of hidden layer (z2) and second set of 3x1 weights
o = self.sigmoid(self.z3) # final activation function
return o
Lastly, we need to define our sigmoid function:
def sigmoid(self, s):
# activation function
return 1/(1+np.exp(-s))
And, there we have it! A (untrained) neural network capable of producing an output.
import numpy as np
# X = (hours sleeping, hours studying), y = score on test
X = np.array(([2, 9], [1, 5], [3, 6]), dtype=float)
y = np.array(([92], [86], [89]), dtype=float)
# scale units
X = X/np.amax(X, axis=0) # maximum of X array
y = y/100 # max test score is 100
class Neural_Network(object):
def __init__(self):
#parameters
self.inputSize = 2
self.outputSize = 1
self.hiddenSize = 3
#weights
self.W1 = np.random.randn(self.inputSize, self.hiddenSize) # (3x2) weight matrix from input to hidden layer
self.W2 = np.random.randn(self.hiddenSize, self.outputSize) # (3x1) weight matrix from hidden to output layer
def forward(self, X):
#forward propagation through our network
self.z = np.dot(X, self.W1) # dot product of X (input) and first set of 3x2 weights
self.z2 = self.sigmoid(self.z) # activation function
self.z3 = np.dot(self.z2, self.W2) # dot product of hidden layer (z2) and second set of 3x1 weights
o = self.sigmoid(self.z3) # final activation function
return o
def sigmoid(self, s):
# activation function
return 1/(1+np.exp(-s))
NN = Neural_Network()
#defining our output
o = NN.forward(X)
print "Predicted Output: \n" + str(o)
print "Actual Output: \n" + str(y)
As you may have noticed, we need to train our network to calculate more accurate results.
Backpropagation
The “learning” of our network
Since we have a random set of weights, we need to alter them to make our inputs equal to the corresponding outputs from our data set. This is done through a method called backpropagation.
Backpropagation works by using a loss function to calculate how far the network was from the target output.
Calculating error
One way of representing the loss function is by using the mean sum squared loss function:
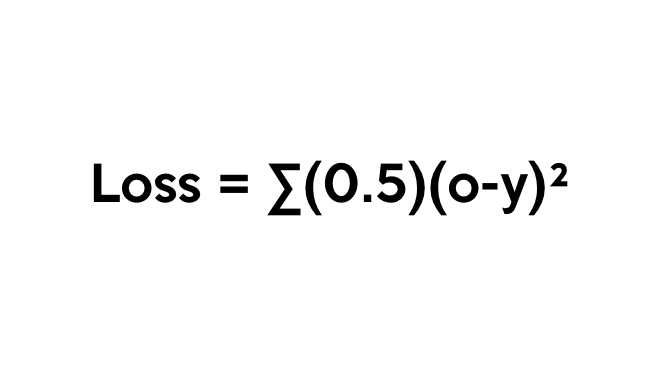
In this function, o is our predicted output, and y is our actual output. Now that we have the loss function, our goal is to get it as close as we can to 0. That means we will need to have close to no loss at all. As we are training our network, all we are doing is minimizing the loss.
To figure out which direction to alter our weights, we need to find the rate of change of our loss with respect to our weights. In other words, we need to use the derivative of the loss function to understand how the weights affect the input.
In this case, we will be using a partial derivative to allow us to take into account another variable.

This method is known as gradient descent. By knowing which way to alter our weights, our outputs can only get more accurate.
Here’s how we will calculate the incremental change to our weights:
1) Find the margin of error of the output layer (o) by taking the difference of the predicted output and the actual output (y)
2) Apply the derivative of our sigmoid activation function to the output layer error. We call this result the delta output sum.
3) Use the delta output sum of the output layer error to figure out how much our z2 (hidden) layer contributed to the output error by performing a dot product with our second weight matrix. We can call this the z2 error.
4) Calculate the delta output sum for the z2 layer by applying the derivative of our sigmoid activation function (just like step 2).
5) Adjust the weights for the first layer by performing a dot product of the input layer with the hidden (z2) delta output sum. For the second layer, perform a dot product of the hidden(z2) layer and the output (o) delta output sum.
Calculating the delta output sum and then applying the derivative of the sigmoid function are very important to backpropagation. The derivative of the sigmoid, also known as sigmoid prime, will give us the rate of change, or slope, of the activation function at output sum.
Let’s continue to code our Neural_Network class by adding a sigmoidPrime (derivative of sigmoid) function:
def sigmoidPrime(self, s):
#derivative of sigmoid
return s * (1 - s)
Then, we’ll want to create our backward propagation function that does everything specified in the four steps above:
def backward(self, X, y, o):
# backward propgate through the network
self.o_error = y - o # error in output
self.o_delta = self.o_error*self.sigmoidPrime(o) # applying derivative of sigmoid to error
self.z2_error = self.o_delta.dot(self.W2.T) # z2 error: how much our hidden layer weights contributed to output error
self.z2_delta = self.z2_error*self.sigmoidPrime(self.z2) # applying derivative of sigmoid to z2 error
self.W1 += X.T.dot(self.z2_delta) # adjusting first set (input --> hidden) weights
self.W2 += self.z2.T.dot(self.o_delta) # adjusting second set (hidden --> output) weights
We can now define our output through initiating foward propagation and intiate the backward function by calling it in the train function:
def train (self, X, y):
o = self.forward(X)
self.backward(X, y, o)
To run the network, all we have to do is to run the train function. Of course, we’ll want to do this multiple, or maybe thousands, of times. So, we’ll use a for loop.
NN = Neural_Network()
for i in xrange(1000): # trains the NN 1,000 times
print "Input: \n" + str(X)
print "Actual Output: \n" + str(y)
print "Predicted Output: \n" + str(NN.forward(X))
print "Loss: \n" + str(np.mean(np.square(y - NN.forward(X)))) # mean sum squared loss
print "\n"
NN.train(X, y)
Great, we now have a Neural Network! What about using these trained weights to predict test scores that we don’t know?
Predictions
To predict our test score for the input of [4, 8], we’ll need to create a new array to store this data, xPredicted.
xPredicted = np.array(([4,8]), dtype=float)
We’ll also need to scale this as we did with our input and output variables:
xPredicted = xPredicted/np.amax(xPredicted, axis=0) # maximum of xPredicted (our input data for the prediction)
Then, we’ll create a new function that prints our predicted output for xPredicted. Believe it or not, all we have to run is forward(xPredicted) to return an output!
def predict(self):
print "Predicted data based on trained weights: ";
print "Input (scaled): \n" + str(xPredicted);
print "Output: \n" + str(self.forward(xPredicted));
To run this function simply call it under the for loop.
NN.predict()
If you’d like to save your trained weights, you can do so with np.savetxt:
def saveWeights(self):
np.savetxt("w1.txt", self.W1, fmt="%s")
np.savetxt("w2.txt", self.W2, fmt="%s")
Here’s the final result:
import numpy as np
# X = (hours studying, hours sleeping), y = score on test, xPredicted = 4 hours studying & 8 hours sleeping (input data for prediction)
X = np.array(([2, 9], [1, 5], [3, 6]), dtype=float)
y = np.array(([92], [86], [89]), dtype=float)
xPredicted = np.array(([4,8]), dtype=float)
# scale units
X = X/np.amax(X, axis=0) # maximum of X array
xPredicted = xPredicted/np.amax(xPredicted, axis=0) # maximum of xPredicted (our input data for the prediction)
y = y/100 # max test score is 100
class Neural_Network(object):
def __init__(self):
#parameters
self.inputSize = 2
self.outputSize = 1
self.hiddenSize = 3
#weights
self.W1 = np.random.randn(self.inputSize, self.hiddenSize) # (3x2) weight matrix from input to hidden layer
self.W2 = np.random.randn(self.hiddenSize, self.outputSize) # (3x1) weight matrix from hidden to output layer
def forward(self, X):
#forward propagation through our network
self.z = np.dot(X, self.W1) # dot product of X (input) and first set of 3x2 weights
self.z2 = self.sigmoid(self.z) # activation function
self.z3 = np.dot(self.z2, self.W2) # dot product of hidden layer (z2) and second set of 3x1 weights
o = self.sigmoid(self.z3) # final activation function
return o
def sigmoid(self, s):
# activation function
return 1/(1+np.exp(-s))
def sigmoidPrime(self, s):
#derivative of sigmoid
return s * (1 - s)
def backward(self, X, y, o):
# backward propgate through the network
self.o_error = y - o # error in output
self.o_delta = self.o_error*self.sigmoidPrime(o) # applying derivative of sigmoid to error
self.z2_error = self.o_delta.dot(self.W2.T) # z2 error: how much our hidden layer weights contributed to output error
self.z2_delta = self.z2_error*self.sigmoidPrime(self.z2) # applying derivative of sigmoid to z2 error
self.W1 += X.T.dot(self.z2_delta) # adjusting first set (input --> hidden) weights
self.W2 += self.z2.T.dot(self.o_delta) # adjusting second set (hidden --> output) weights
def train(self, X, y):
o = self.forward(X)
self.backward(X, y, o)
def saveWeights(self):
np.savetxt("w1.txt", self.W1, fmt="%s")
np.savetxt("w2.txt", self.W2, fmt="%s")
def predict(self):
print "Predicted data based on trained weights: ";
print "Input (scaled): \n" + str(xPredicted);
print "Output: \n" + str(self.forward(xPredicted));
NN = Neural_Network()
for i in xrange(1000): # trains the NN 1,000 times
print "# " + str(i) + "\n"
print "Input (scaled): \n" + str(X)
print "Actual Output: \n" + str(y)
print "Predicted Output: \n" + str(NN.forward(X))
print "Loss: \n" + str(np.mean(np.square(y - NN.forward(X)))) # mean sum squared loss
print "\n"
NN.train(X, y)
NN.saveWeights()
NN.predict()
To see how accurate the network actually is, I ran trained it 100,000 times to see if it would ever get exactly the right output. Here’s what I got:
# 99999
Input (scaled):
[[ 0.66666667 1. ]
[ 0.33333333 0.55555556]
[ 1. 0.66666667]]
Actual Output:
[[ 0.92]
[ 0.86]
[ 0.89]]
Predicted Output:
[[ 0.92]
[ 0.86]
[ 0.89]]
Loss:
1.94136958194e-18
Predicted data based on trained weights:
Input (scaled):
[ 0.5 1. ]
Output:
[ 0.91882413]
There you have it! A full-fledged neural network that can learn and adapt to produce accurate outputs. While we thought of our inputs as hours studying and sleeping, and our outputs as test scores, feel free to change these to whatever you like and observe how the network adapts! After all, all the network sees are the numbers. The calculations we made, as complex as they seemed to be, all played a big role in our learning model. If you think about it, it’s super impressive that your computer, a physical object, managed to learn by itself!
If you want to see how this network can be applied to digit recognition, you can take a look at my implementation of it here.
Make sure to stick around for more machine learning tutorials on other models like Linear Regression and Classification coming soon!